4.9 KiB
Running Ultralytics YOLOv8 with TFLite Runtime
This guide demonstrates how to perform inference using an Ultralytics YOLOv8 model exported to the TensorFlow Lite (TFLite) format. TFLite is a popular choice for deploying machine learning models on mobile, embedded, and IoT devices due to its optimization for on-device inference with low latency and a small binary size. This example supports FP32, FP16, and INT8 quantized TFLite models.
⚙️ Installation
Before running inference, you need to install the necessary TFLite interpreter package. Choose the appropriate package based on your hardware (CPU or GPU).
Installing tflite-runtime (Recommended for Edge Devices)
The tflite-runtime package is a smaller package that includes the bare minimum required to run inferences with TensorFlow Lite, primarily the Interpreter Python class. It's ideal for resource-constrained environments like Raspberry Pi or Coral Edge TPU.
pip install tflite-runtime
For more details, refer to the official TFLite Python quickstart guide.
Installing Full tensorflow Package (CPU or GPU)
Alternatively, you can install the full TensorFlow package. This includes the TFLite interpreter along with the complete TensorFlow library.
-
CPU-Only: Suitable if you don't have an NVIDIA GPU or don't need GPU acceleration.
pip install tensorflow -
GPU Support: To leverage NVIDIA GPU acceleration for potentially faster inference, install
tensorflowwith GPU support. Ensure you have the necessary NVIDIA drivers and CUDA toolkit installed.# Check TensorFlow documentation for specific CUDA/cuDNN version requirements pip install tensorflow[and-cuda] # Or follow specific instructions on TF website
Visit the official TensorFlow installation guide for detailed instructions, including GPU setup.
🚀 Usage
Follow these steps to run inference with your exported YOLOv8 TFLite model.
-
Export YOLOv8 Model to TFLite: First, export your trained Ultralytics YOLOv8 model (e.g.,
yolov8n.pt) to the TFLite format using theyolo exportcommand. This example exports an INT8 quantized model for optimal performance on edge devices. You can also export FP32 or FP16 models by adjusting theformatand quantization arguments. Refer to the Ultralytics Export mode documentation for more options.yolo export model=yolov8n.pt imgsz=640 format=tflite int8=True # Exports yolov8n_saved_model/yolov8n_full_integer_quant.tfliteThe export process will create a directory (e.g.,
yolov8n_saved_model) containing the.tflitemodel file and potentially ametadata.yamlfile with class names and other model details. -
Run Inference Script: Execute the provided Python script (
main.py) to perform inference on an image. Adjust the arguments as needed for your specific model path, image source, confidence threshold, and IoU threshold.python main.py \ --model yolov8n_saved_model/yolov8n_full_integer_quant.tflite \ --img image.jpg \ --conf 0.25 \ --iou 0.45 \ --metadata yolov8n_saved_model/metadata.yaml--model: Path to the exported.tflitemodel file.--img: Path to the input image for detection.--conf: Minimum confidence threshold for detections (e.g., 0.25).--iou: Intersection over Union (IoU) threshold for Non-Maximum Suppression (NMS).--metadata: Path to themetadata.yamlfile generated during export (contains class names).
✅ Output
The script will process the input image using the specified TFLite model and display the image with bounding boxes drawn around detected objects. Each box will be labeled with the predicted class name and confidence score.
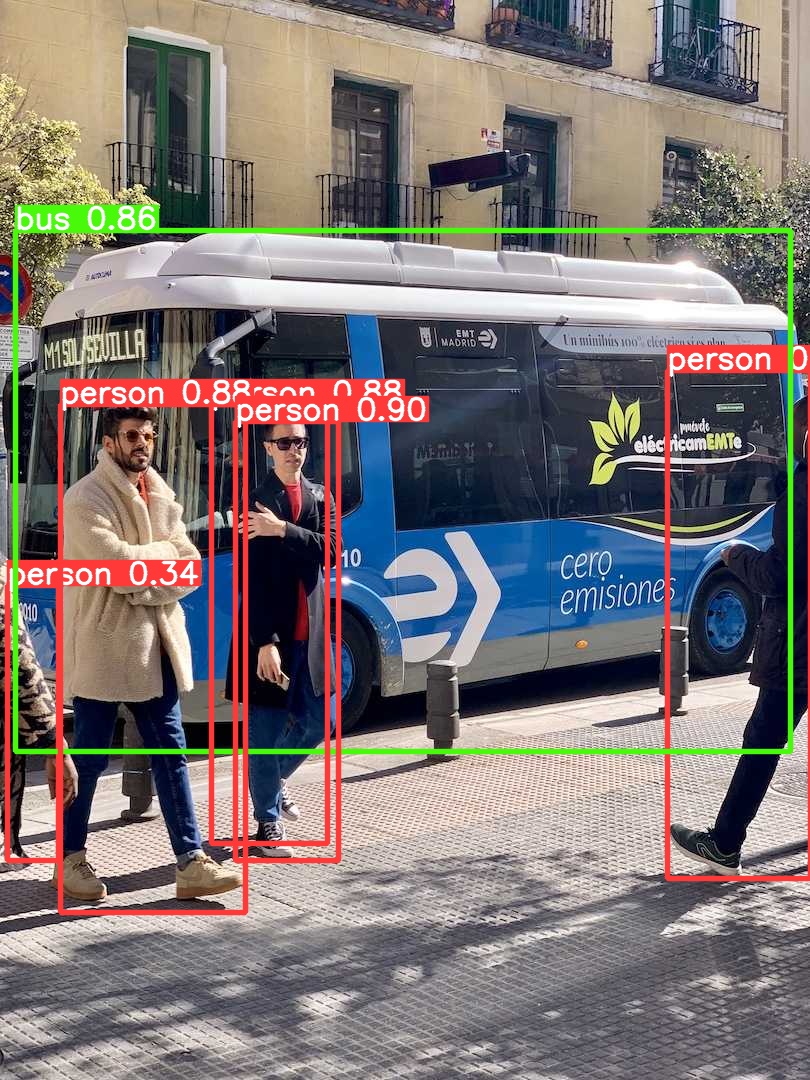
This example provides a straightforward way to deploy Ultralytics YOLOv8 models on devices supporting TFLite, enabling efficient object detection in various applications. Explore different quantization options and model sizes to find the best balance between performance and accuracy for your specific use case.
🤝 Contribute
Contributions to enhance this example or add new functionalities are welcome! Feel free to fork the Ultralytics repository, make your changes, and submit a pull request.